
后训练中的RL已死?MIT新算法挑战传统后训练思维,谢赛宁转发
后训练中的RL已死?MIT新算法挑战传统后训练思维,谢赛宁转发在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
来自主题: AI技术研报
6661 点击 2026-03-16 14:26
 搜索
搜索
在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
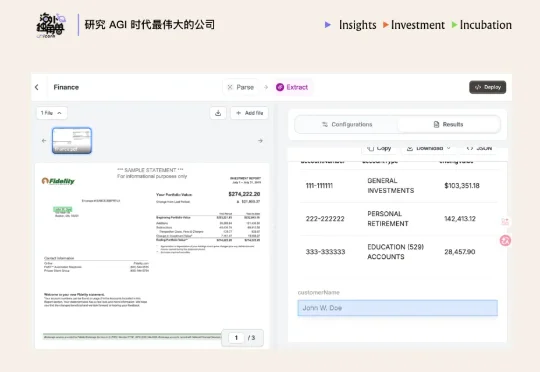
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
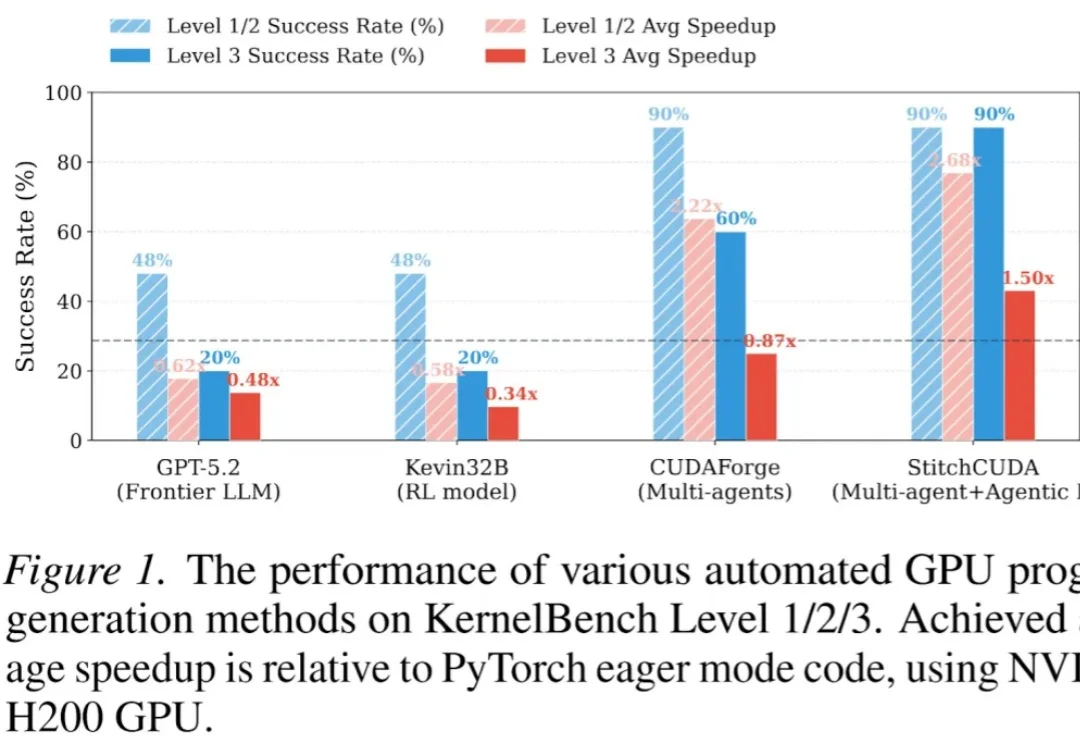
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

我天!感觉 Seed 1.8 发布还没多久,没想到 Doubao-Seed-2.0 这么快就杀到了…今天发都算是晚讯了。据官方介绍,这次 Seed 2.0 多模态理解能力全面升级,还强化了 LLM 与 Agent 能力,模型在真实长链路任务中可以稳定推进。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。
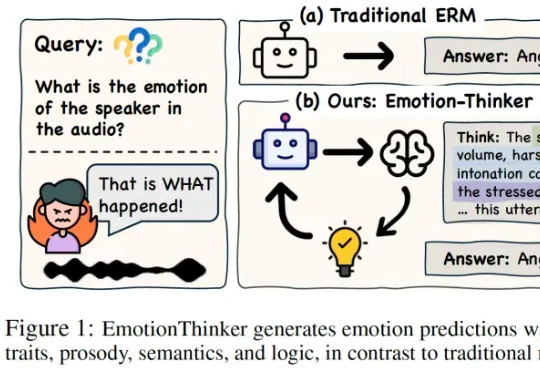
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?

过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
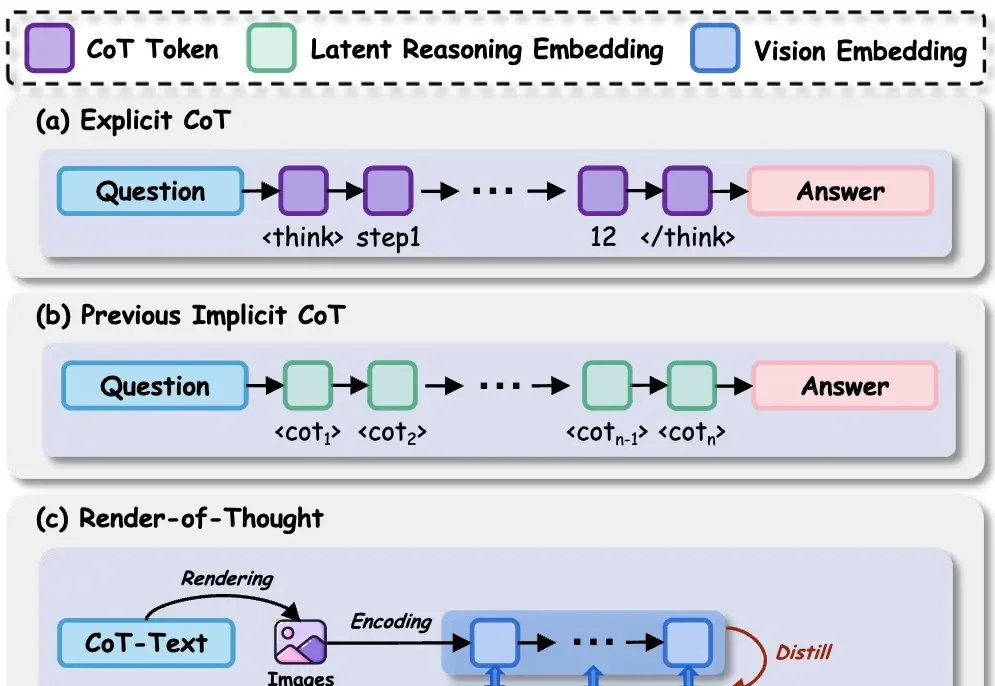
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。